Var Section = Await Reader.readnextsectionasync(); Error Upload Files
What's the big deal about file uploads? Well, the big bargain is that information technology is a catchy operation. Implement file uploads in the incorrect way, and you may end up with retention leaks, server slowdowns, out-of-retention errors, and worst of all unhappy users.
With Azure Blob Storage, there multiple unlike means to implement file uploads. But if you want to let your users upload large files you will almost certainly want to practise information technology using streams. Yous'll find a lot of file upload examples out at that place that use what I phone call the "pocket-sized file" methods, such as IFormFile, or using a byte array, a memory stream buffer, etc. These are fine for small files, but I wouldn't recommend them for file sizes over 2MB. For larger file size situations, we need to be much more careful well-nigh how we process the file.
What NOT to do
Here are some of the Don'ts for .Cyberspace MVC for uploading large files to Azure Hulk Storage
DON'T practice information technology if you don't take to
You may exist able to use client-side straight uploads if your architecture supports generating SAS (Shared Access Signature) upload Uris, and if y'all don't need to procedure the upload through your API. Handling large file uploads is circuitous and before tackling information technology, y'all should see if you can offload that functionality to Azure Blob Storage entirely.
DON'T use IFormFile for big files
If you lot let MVC attempt to demark to an IFormFile, information technology will effort to spool the entire file into memory. Which is exactly what we don't want to do with large files.
DON'T model bind at all, in fact
MVC is very good at model binding from the web request. Just when it comes to files, any sort of model binding will try to…you guessed it, read the entire file into retentiveness. This is slow and it is wasteful if all we want to do is frontwards the data right on to Azure Blob Storage.
DON'T use any retentivity streams
This one should exist kind of obvious, considering what does a retention stream exercise? Yep, read the file into retention. For the same reasons as above, nosotros don't want to do this.
DON'T apply a byte array either
Yep, same reason. Your byte array volition work fine for small files or light loading, simply how long volition yous have to wait to put that large file into that byte assortment? And if there are multiple files? But don't do information technology, there is a improve way.
So what are the DOs?
There is ane example in Microsoft'southward documentation that covers this topic very well for .NET MVC, and it is here, in the final section about large files. In fact, if you are reading this article I highly recommend you read that unabridged document and the related case because it covers the large file vs small file differences and has a lot of great information. And merely go ahead and download the whole example, because it has some of the pieces we need. At the fourth dimension of this article, the latest version of the sample code available is for .NET Core iii.0 but the pieces we demand volition piece of work just fine with .Internet 5.
The other piece we need is getting the file to Azure Blob Storage during the upload process. To practice that, we are going to use several of the helpers and guidance from the MVC example on file uploads. Here are the important parts.
Practise use a multipart course-data asking
You'll see this in the file upload example. Multipart (multipart/form-information) requests are a special blazon of request designed for sending streams, that can also support sending multiple files or pieces of data. I think the explanation in the swagger documentation is besides actually helpful to sympathise this blazon of request.
The multipart request (which tin actually be for a single file) can be read with a MultipartReader that does NOT need to spool the body of the asking into memory. By using the multipart grade-data request you lot can also back up sending additional data through the request.
It is important to annotation that although information technology has "multi-function" in the name, the multipart request does non mean that a unmarried file will be sent in parts. Information technology is not the same every bit file "chunking", although the proper noun sounds similar. Chunking files is a separate technique for file uploads – and if you need some features such as the ability to break and restart or retry partial uploads, chunking may be the way you demand to get.
DO prevent MVC from model-bounden the request
The case linked above has an attribute class that works perfectly for this: DisableFormValueModelBindingAttribute.cs. With it, we can disable the model bounden on the Controller Action that we want to apply.
DO increase or disable the request size limitation
This depends on your requirements. Yous can set the size to something reasonable depending on the file sizes you want to permit. If you go larger than 256MB (the current max for single cake upload for blob storage), you may need to exercise the streaming setup described here and As well chunk the files across blobs. Exist sure to read the most current documentation to brand sure your file sizes are supported with the method you choose.
/// <summary> /// Upload an document using our streaming method /// </summary> /// <returns>A collection of document models</returns> [DisableFormValueModelBinding] [ProducesResponseType(typeof(Listing<DocumentModel>), 200)] [DisableRequestSizeLimit] [HttpPost("streamupload")] public async Task<IActionResult> UploadDocumentStream() ... DO process the boundaries of the request and send the stream to Azure Blob Storage
Again, this comes mostly from Microsoft'south example, with some special processing to copy the stream of the request body for a single file to Azure Hulk Storage. The file content blazon tin can exist read without touching the stream, along with the filename. Just remember, neither of these can ever be trusted. Y'all should encode the filename and if yous really want to prevent unauthorized types, you could get fifty-fifty further by calculation some checking to read the start few bytes of the stream and verify the type.
var sectionFileName = contentDisposition.FileName.Value; // employ an encoded filename in case there is anything weird var encodedFileName = WebUtility.HtmlEncode(Path.GetFileName(sectionFileName)); // at present make information technology unique var uniqueFileName = $"{Guid.NewGuid()}_{encodedFileName}"; // read the section filename to become the content type var fileContentType = MimeTypeHelper.GetMimeType(sectionFileName); // bank check the mime blazon against our list of allowed types var enumerable = allowedTypes.ToList(); if (!enumerable.Contains(fileContentType.ToLower())) { return new ResultModel<List<DocumentModel>>("fileType", "File type not immune: " + fileContentType); } Practice await at the last position of the stream to get the file size
If y'all want to go or save the filesize, yous can check the position of the stream after uploading it to blob storage. Do this instead of trying to go the length of the stream beforehand.
DO remove whatever signing central from the Uri i if y'all are preventing direct downloads
The Uri that is generated as part of the blob will include an access token at the end. If you don't want to permit your users have straight blob access, you can trim this role off.
// fob to get the size without reading the stream in memory var size = section.Body.Position; // check size limit in instance somehow a larger file got through. nosotros can't do it until after the upload because we don't want to put the stream in memory if (maxBytes < size) { await blobClient.DeleteIfExistsAsync(); return new ResultModel<List<DocumentModel>>("fileSize", "File too large: " + encodedFileName); } var doc = new DocumentModel() { FileName = encodedFileName, MimeType = fileContentType, FileSize = size, // Practise Not include Uri query since it has the SAS credentials; This will return the URL without the querystring. // UrlDecode to convert %2F into "/" since Azure Storage returns it encoded. This prevents the folder from being included in the filename. Url = WebUtility.UrlDecode(blobClient.Uri.GetLeftPart(UriPartial.Path)) }; Practice use a stream upload method to hulk storage
There are multiple upload methods available, simply make sure you choose one that has an input of a Stream, and use the department.Body stream to send the upload.
var blobClient = blobContainerClient.GetBlobClient(uniqueFileName); // utilise a CloudBlockBlob because both BlobBlockClient and BlobClient buffer into memory for uploads CloudBlockBlob blob = new CloudBlockBlob(blobClient.Uri); expect blob.UploadFromStreamAsync(section.Body); // set the type later the upload, otherwise will get an error that blob does not exist await blobClient.SetHttpHeadersAsync(new BlobHttpHeaders { ContentType = fileContentType }); Practice performance-profile your results
This may be the most important pedagogy. Afterward y'all've written your lawmaking, run it in Release mode using the Visual Studio Performance Profiling tools. Compare your profiling results to that of a known memory-eating method, such as an IFormFile. Beware that different versions of the Azure Hulk Storage library may perform differently. And different implementations may perform differently besides! Here were some of my results.
To do this simple profiling, I used PostMan to upload multiple files of around 20MB in several requests. Past using a collection, or past opening multiple tabs, you can submit multiple requests at a time to come across how the memory of the application is consumed.

Offset, using an IFormFile. You can meet the memory usage increases quickly for each request using this method.
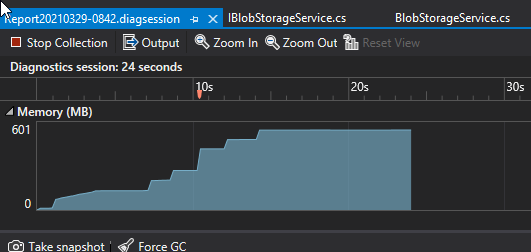
Next, using the latest version (v12) of the Azure Blob Storage libraries and a Stream upload method. Notice that it'south not much better than IFormFile! Although BlobStorageClient is the latest way to collaborate with hulk storage, when I await at the memory snapshots of this operation it has internal buffers (at least, at the fourth dimension of this writing) that cause it to not perform too well when used in this manner.
var blobClient = blobContainerClient.GetBlobClient(uniqueFileName); expect blobClient.UploadAsync(section.Torso);
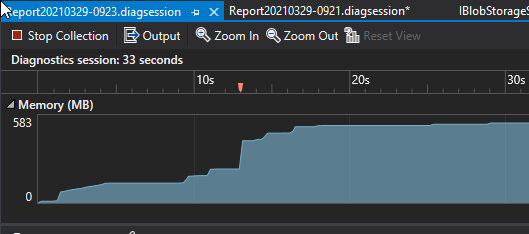
Simply, using almost identical code and the previous library version that uses CloudBlockBlob instead of BlobClient, nosotros tin see a much improve memory performance. The same file uploads outcome in a small increase (due to resources consumption that eventually goes back downward with garbage collection), but nothing near the ~600MB consumption similar in a higher place. I'grand sure whatever memory issues exist with the latest libraries will be resolved eventually, but for now, I will employ this method.
// use a CloudBlockBlob considering both BlobBlockClient and BlobClient buffer into memory for uploads CloudBlockBlob hulk = new CloudBlockBlob(blobClient.Uri); await blob.UploadFromStreamAsync(section.Body);

For your reference, here is a version of the upload service methods from that concluding profiling result:
/// <summary> /// Upload multipart content from a request body /// </summary> /// <param proper noun="requestBody">body stream from the request</param> /// <param proper name="contentType">content blazon from the request</param> /// <returns></returns> public async Chore<ResultModel<List<DocumentModel>>> UploadMultipartDocumentRequest(Stream requestBody, cord contentType) { // configuration values hardcoded here for testing var bytes = 104857600; var types = new Listing<string>{ "awarding/pdf", "image/jpeg", "paradigm/png"}; var docs = look this.UploadMultipartContent(requestBody, contentType, types, bytes); if (docs.Success) { foreach (var doctor in docs.Result) { // here we could save the document data to a database for tracking if (doc?.Url != null) { Debug.WriteLine($"Document saved: {doc.Url}"); } } } return docs; } /// <summary> /// Upload multipart content from a request trunk /// based on microsoft example https://github.com/dotnet/AspNetCore.Docs/tree/main/aspnetcore/mvc/models/file-uploads/samples/ /// and large file streaming example https://docs.microsoft.com/en-us/aspnet/core/mvc/models/file-uploads?view=aspnetcore-v.0#upload-large-files-with-streaming /// tin can accept multiple files in multipart stream /// </summary> /// <param name="requestBody">the stream from the request torso</param> /// <param name="contentType">content type from the request</param> /// <param name="allowedTypes">listing of allowed file types</param> /// <param name="maxBytes">max bytes immune</param> /// <returns>a drove of document models</returns> public async Chore<ResultModel<Listing<DocumentModel>>> UploadMultipartContent(Stream requestBody, cord contentType, Listing<cord> allowedTypes, int maxBytes) { // Check if HttpRequest (Grade Data) is a Multipart Content Blazon if (!IsMultipartContentType(contentType)) { render new ResultModel<List<DocumentModel>>("requestType", $"Expected a multipart request, but got {contentType}"); } FormOptions defaultFormOptions = new FormOptions(); // Create a Collection of KeyValue Pairs. var formAccumulator = new KeyValueAccumulator(); // Decide the Multipart Boundary. var boundary = GetBoundary(MediaTypeHeaderValue.Parse(contentType), defaultFormOptions.MultipartBoundaryLengthLimit); var reader = new MultipartReader(purlieus, requestBody); var department = wait reader.ReadNextSectionAsync(); List<DocumentModel> docList = new Listing<DocumentModel>(); var blobContainerClient = GetBlobContainerClient(); // Loop through each 'Department', starting with the current 'Section'. while (section != cypher) { // Check if the current 'Department' has a ContentDispositionHeader. var hasContentDispositionHeader = ContentDispositionHeaderValue.TryParse(section.ContentDisposition, out ContentDispositionHeaderValue contentDisposition); if (hasContentDispositionHeader) { if (HasFileContentDisposition(contentDisposition)) { try { var sectionFileName = contentDisposition.FileName.Value; // use an encoded filename in case there is anything weird var encodedFileName = WebUtility.HtmlEncode(Path.GetFileName(sectionFileName)); // now make it unique var uniqueFileName = $"{Guid.NewGuid()}_{encodedFileName}"; // read the department filename to go the content type var fileContentType = MimeTypeHelper.GetMimeType(sectionFileName); // check the mime type against our list of allowed types var enumerable = allowedTypes.ToList(); if (!enumerable.Contains(fileContentType.ToLower())) { return new ResultModel<List<DocumentModel>>("fileType", "File blazon non allowed: " + fileContentType); } var blobClient = blobContainerClient.GetBlobClient(uniqueFileName); // employ a CloudBlockBlob because both BlobBlockClient and BlobClient buffer into retention for uploads CloudBlockBlob hulk = new CloudBlockBlob(blobClient.Uri); look blob.UploadFromStreamAsync(section.Body); // set up the type after the upload, otherwise will get an error that blob does not be await blobClient.SetHttpHeadersAsync(new BlobHttpHeaders { ContentType = fileContentType }); // fob to go the size without reading the stream in retentivity var size = section.Body.Position; // check size limit in instance somehow a larger file got through. we can't do it until afterwards the upload considering we don't want to put the stream in memory if (maxBytes < size) { await blobClient.DeleteIfExistsAsync(); return new ResultModel<Listing<DocumentModel>>("fileSize", "File too big: " + encodedFileName); } var physician = new DocumentModel() { FileName = encodedFileName, MimeType = fileContentType, FileSize = size, // Do Non include Uri query since it has the SAS credentials; This will return the URL without the querystring. // UrlDecode to convert %2F into "/" since Azure Storage returns it encoded. This prevents the binder from being included in the filename. Url = WebUtility.UrlDecode(blobClient.Uri.GetLeftPart(UriPartial.Path)) }; docList.Add(doc); } catch (Exception e) { Panel.Write(eastward.Message); // could be specific azure error types to look for hither return new ResultModel<Listing<DocumentModel>>(null, "Could not upload file: " + e.Bulletin); } } else if (HasFormDataContentDisposition(contentDisposition)) { // if for some reason other form information is sent information technology would get processed here var key = HeaderUtilities.RemoveQuotes(contentDisposition.Name); var encoding = GetEncoding(section); using (var streamReader = new StreamReader(section.Torso, encoding, detectEncodingFromByteOrderMarks: truthful, bufferSize: 1024, leaveOpen: true)) { var value = await streamReader.ReadToEndAsync(); if (String.Equals(value, "undefined", StringComparison.OrdinalIgnoreCase)) { value = String.Empty; } formAccumulator.Append(key.Value, value); if (formAccumulator.ValueCount > defaultFormOptions.ValueCountLimit) { return new ResultModel<List<DocumentModel>>(null, $"Form central count limit {defaultFormOptions.ValueCountLimit} exceeded."); } } } } // Begin reading the next 'Department' inside the 'Body' of the Request. department = look reader.ReadNextSectionAsync(); } return new ResultModel<List<DocumentModel>>(docList); } I hope you observe this useful as you tackle file upload operations of your own.
Source: https://trailheadtechnology.com/dos-and-donts-for-streaming-file-uploads-to-azure-blob-storage-with-net-mvc/
; Error Upload Files){kind=link}
Post a Comment for "Var Section = Await Reader.readnextsectionasync(); Error Upload Files"